
A question I'm often asked by potential clients is: do you use traditional computer vision technologies for your core computer vision technologies, or do you use deep learning?
A quick background - traditional computer vision technologies work by using algorithms such as hough circles, contour recognition, canny edge detection etc to pull artifacts from images. These algorithms have been around for a while (some developed back in the 70's) and are mostly robust and efficient.
A typical approach for these algorithms, e.g. in the case of canny edge detection, is to utilise math to try and work out higher order information from an image. In the example of canny edge detection we take (among other functions) the first derivative across the image in order to find the rate of change of color gradient: in more simple terms, we are looking for a sudden change in color or brightness across an image; this may highlight an edge.

Example of Canny's gradient test, rate of change of brighness is applied, where the change is highest is the likelyhood of an 'edge' in the image
Deep Learning technologies are somewhat newer. With deep learning we are using neural networks to extract higher order information from an image similar to the above, but in the case of neural networks the data structures are notably more complex, and they are capable of learning and refining themselves as they are given more data.
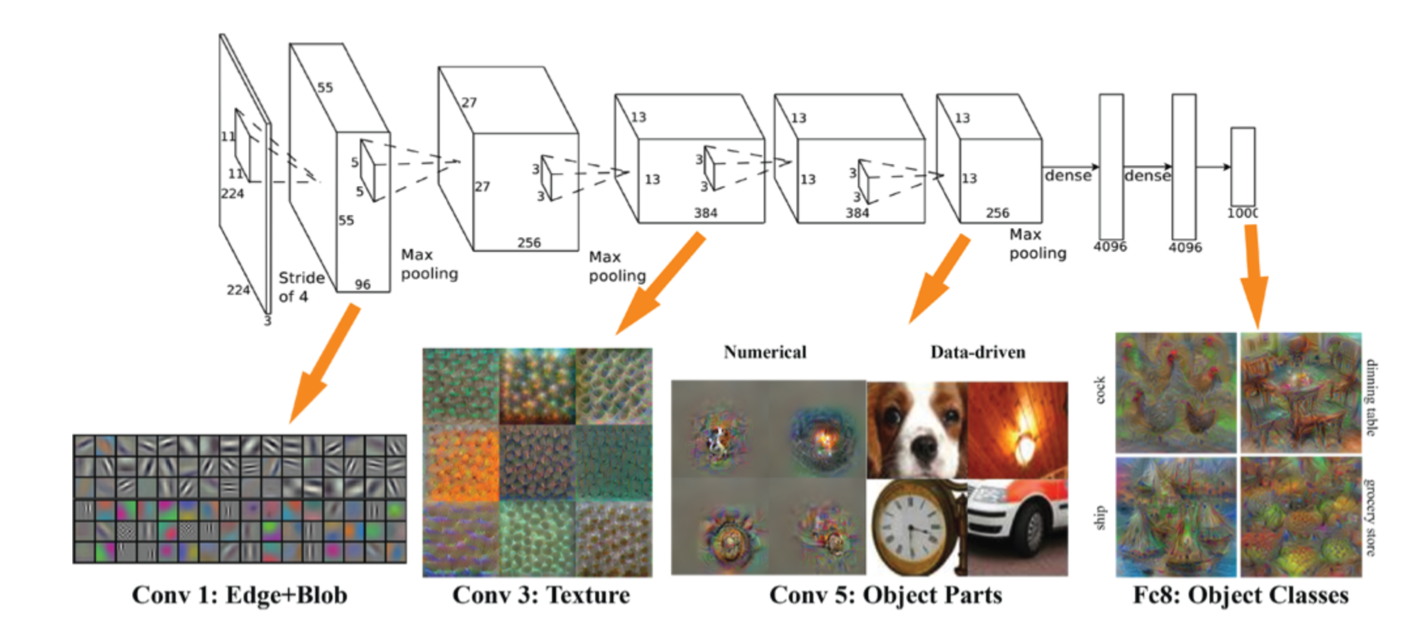
Convolutional neural net of the VGGnet family, showing higher order feature extraction
The answer is: both. Traditional computer vision algorithms are fast and relatively efficient, however one typically has to resort to case based AI techniques or decision trees in order to make a classification. Deep Learning has amazing capabilities for image analysis, however can fail when the problem is more complex than a single classification (e.g. 'show me all the dogs in this picture'), as well as be computationally expensive.
Most of our core vision technologies use a stack: the stack being traditional computer vision technologies to take candidates from an image using a mix of algorithm (depending on the problem being solved, e.g. perhaps soem image normalisation, then perhaps hough circles to extract circles, and then maybe even SIFT to identify more complex artefacts), and these candidates are then sent to the deep learning models for classification. This approach is borrowed from how people typically process information - you may look at a where's Waldo puzzle initally looking for red and white stripes, and then once you see an area with red and white stripes, look closer and with more concentration, work out if it is Waldo or not.